Missing Context
AI guesses across service boundaries when repository and system context is thin.
Bring order to chaotic, unverified AI prompting. Our Quality Agents automatically wrap every coding run in deep architectural context and rigorous testing, turning random AI guesses into something valuable.
Engineers still control the merge. They just spend less time cleaning up broken AI output.
Most AI code tools push blind guesses, broken commands, and bloated diffs straight to review. MergeLoom changes that. Our Quality Agents handle the entire cleanup process before handoff, delivering pure, review-ready code.
AI guesses across service boundaries when repository and system context is thin.
Specialist review agents catch invented behavior, weak assumptions, and off-scope edits before handoff.
Setup, test, lint, typecheck, and custom commands run before the branch reaches review.
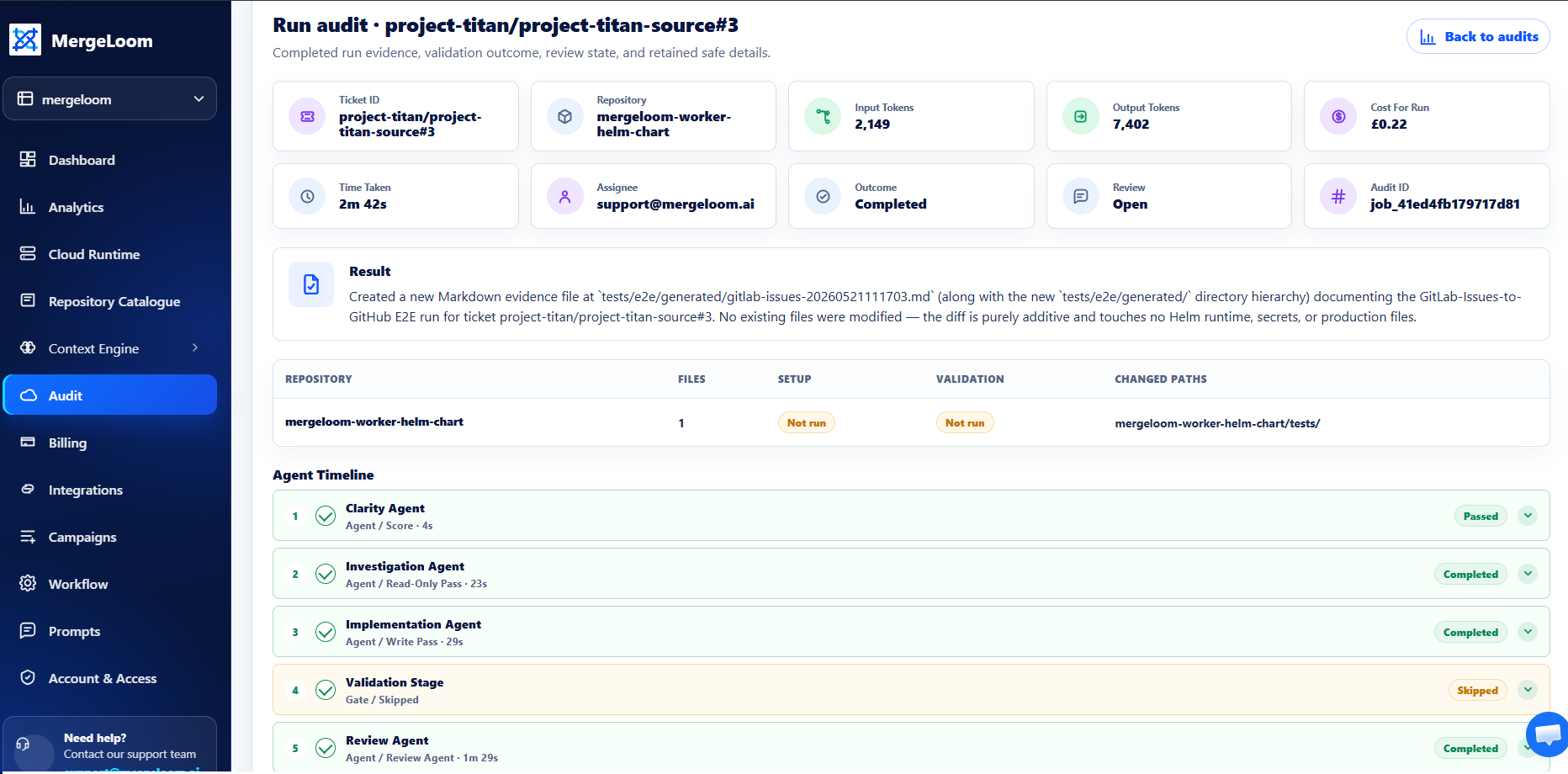
Repair attempts, Diff Guard status, validation output, and handoff evidence stay attached to the run.
Each step kills a different type of code failure before a single PR is ever opened. The AI handles the heavy lifting, but your engineers always keep the final say.
The run starts with the approved work item, system context, repository rules, and acceptance criteria.
Each gate removes a different kind of AI failure before the branch reaches engineers.
Stops vague tickets and missing acceptance criteria before coding starts.
Reads target files, system context, docs, and related services first.
Runs setup, lint, typecheck, tests, builds, or configured commands.
Uses failures to make bounded fixes, then reruns the relevant checks.
Checks product fit, technical risk, evidence, and review quality.
Blocks oversized or off-scope changes before handoff.
Engineers receive a smaller, checked branch with the evidence needed to review quickly.
Configured commands ran before the review request opened.
Failed checks and bounded repair attempts stay visible.
Reviewer sees scope, context, risks, and Diff Guard status.
Standard PR/MR bots only complain after a branch is already waiting on your team. MergeLoom intercepts the chaos early, checking ticket scope, running validation, and auto-repairing bugs before handoff so reviewers never waste a second.
Your custom repository commands run entirely in the background before a PR ever reaches an engineer.
Smart repair loops automatically target and fix validation failures without letting the ticket scope creep.
Product fit, technical risk, and overall code quality agents inspect the exact same diff simultaneously.
Quality Agents prepare a pristine branch, but your existing code host and merge rules hold the final approval.
Get full visibility on every run. See exactly how our agents handled ticket clarity, repository investigations, validation gates, auto-repairs, and final diff metrics in one place.
Quality Agents kill review hell without touching your existing branch protection, approval rules, or merge ownership.
MergeLoom prepares review-ready PRs/MRs. Your team decides what is merged.
Validation follows the setup, test, lint, typecheck, and custom commands configured for each repository.
Developers still review the final branch in GitHub, GitLab, or Azure Repos.
Quality Agent results, validation output, repair attempts, and review findings stay attached to the run.
Most AI tools fail because they code in the dark. Quality Agents bridge the gap, giving AI the context, validation gates, and auto-repair loops it needs to tackle complex tasks like legacy maintenance, sprawling bug fixes, and documentation updates entirely in the background.
Patch reproducible issues, run validation, and hand off a cleaner branch.
Generate tests against acceptance criteria and keep the validation evidence attached.
Catch syntax, lint, and command failures before infrastructure edits reach review.
Flag scope drift and changed-line volume before a refactor gets too wide.
Move dependency updates and housekeeping through checks before reviewers spend time.
Apply acceptance criteria, validation gates, and specialist review across larger workstreams.
No. They remove cleanup before review. Engineers still approve and merge through the normal PR/MR process.
No. They run validation and specialist review passes, then hand the final decision to your engineering team.
They run in the configured execution path: MergeLoom-managed infrastructure for Cloud Hosted, or your worker for Self Hosted.
It gives Investigation and Review Agents whole-system context: related services, API relationships, docs, rules, and evidence.
Run MergeLoom on scoped work before rolling it out. You only pay when a run opens a PR/MR for review, not for seats or tickets that stop before handoff.
Cloud
Then From £4 Per PR/MR
Self Hosted
Then From £2 Per PR/MR
Paid Outcomes
No PR/MR, No Run Charge
No PR/MR, No Run Charge · No Seat Pricing · Human Review Stays In Control