Prompt Guesswork
Manual prompting depends entirely on who writes it, meaning AI constantly misses rules hidden in docs, prior runs, or adjacent services.
Context Engine maps your entire architecture—from documentation to cross-repository API relationships. It packages everything into a secure knowledge base, keeping the AI's context fresh as your code changes so it never has to guess.
After the first index, refresh jobs estimate changed files and AI credits before updating stale context, so agents stop rediscovering the architecture on every run.
AI coding output completely falls apart when every run has to guess at your architecture, stale documentation, and service relationships.
Manual prompting depends entirely on who writes it, meaning AI constantly misses rules hidden in docs, prior runs, or adjacent services.
Contextless AI burns expensive tokens re-reading files, routes, and service dependencies on every single run instead of using reusable system knowledge.
Merged changes quickly leave indexed documentation behind unless your AI context automatically refreshes against the latest repository state.
A run locked to a single repository blindly misses critical context from your shared packages, APIs, background workers, and downstream services.
Stop coding in multi-repository blind spots. Context Engine indexes your ecosystem once and self-updates as code changes. When a run starts, the agent queries it to grab a surgical, bounded context pack for that exact task—giving you cross-repository intelligence with zero token waste.
Context Engine starts with repositories, docs, and knowledge sources your team explicitly approves.
Target repos, related services, shared packages, workers, and APIs.
Architecture notes, repository docs, AGENTS.md, and selected Markdown.
Selected pages join the same evidence path as code context.
Include, exclude, and scope controls decide what enters the vault.
Reusable architecture memory connects files, symbols, APIs, events, docs, and service relationships before a run starts.
Upstream APIs, downstream services, packages, events, and background jobs.
Exact paths, commits, snippets, docs, and indexed baseline state.
Repository guidance, validation commands, file patterns, and coding rules.
Changed and deleted files update stale context without full rediscovery.
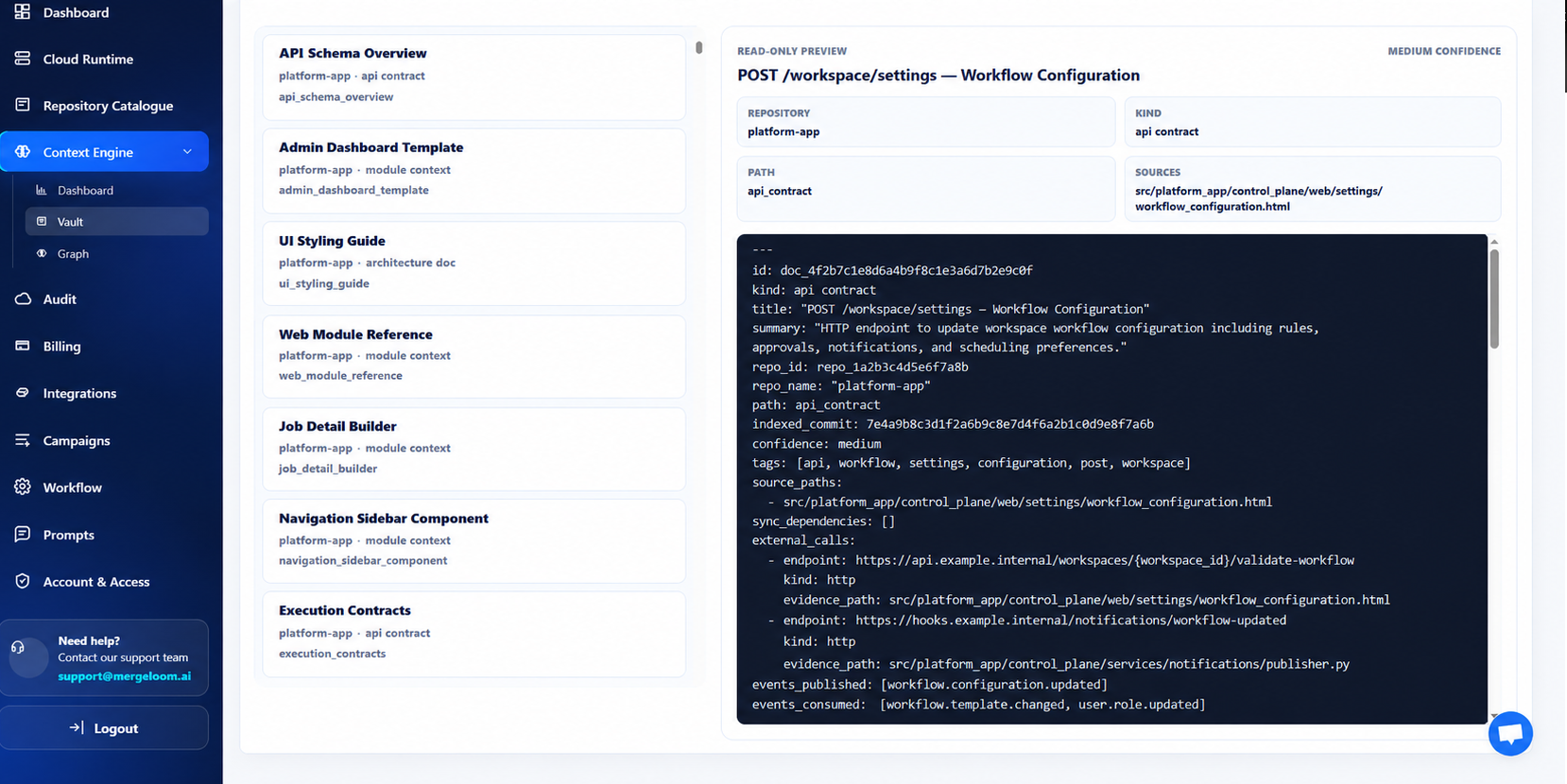
Indexed source evidence, relationship graph, summaries, commits, and confidence.
Agents receive only the context needed for the job, with source reasons attached.
Relevant services, contracts, and dependencies arrive before code changes.
Every packed context item explains why it was included.
Indexed commits and stale-context state stay visible.
Context is selected and bounded rather than dumped into the run.
Prompt stuffing blindly dumps thousands of lines of code into a chat window and hopes for the best. Context Engine does the opposite—it acts as an on-demand search engine, surgically pulling a precise, token-efficient context pack only when the agent needs it.
Architecture rules, API contracts, and indexed commits are stored globally so they are instantly available across every run instead of trapped in one chat window.
After a one-time baseline index, the system self-updates by strictly tracking added, modified, and deleted files instead of processing everything from scratch.
Sprawling repositories are indexed together, making shared packages, downstream services, and event pipelines visible before coding ever starts.
Every context pack carries exact source paths, confidence metrics, and indexed commit histories right to the PR for easy human review.
Your complete system knowledge in one place. Instantly review indexed code sources, system coverage, and active run context packs right from the UI.
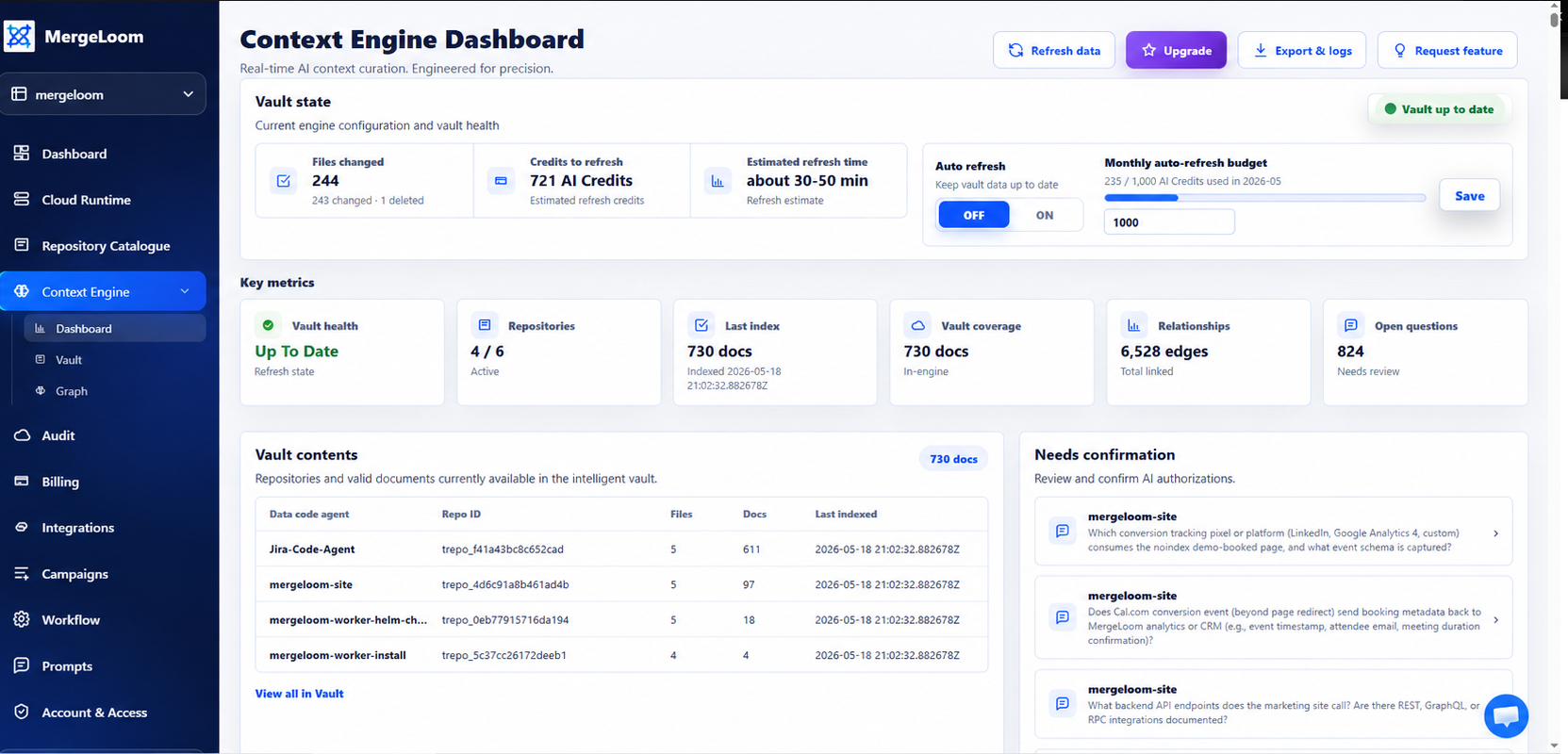
No runaway cloud bills or unapproved repository access. Scope what your AI sees, control refresh schedules, and track every dollar of context spend in real time.
Only configured repositories, docs, related services, include patterns, and context sources are used for indexing and run context.
Workers receive authorized repository IDs, and runtime search rejects context outside that job scope.
Enable auto refresh with a monthly AI-credit budget, so stale context updates inside cost limits.
Self Hosted runs Context Engine beside your worker with a private vault volume and repository cache. We never train models on your data.
Stop letting AI guess at your architecture. This is built specifically for tasks that need an exact, real-time understanding of your team conventions, validation rules, and cross-service dependencies.
Index related repositories together so runs understand shared packages, upstream APIs, workers, events, and downstream services.
Attach routes, dependencies, symbols, patterns, docs, and validation expectations before implementation starts.
Show which vault docs, source paths, commits, and context-pack snippets shaped a PR/MR.
Bring selected Confluence pages into the same indexed context path as repository knowledge.
Avoid full rediscovery on every run with reusable vault docs, changed-file refresh, and scoped context packs.
Give investigation, validation, and review agents the same run evidence before they judge output.
No. It uses search, but the product is not a generic retrieval wrapper. Context Engine indexes approved sources into vault documents, builds graph evidence across repositories, services, and APIs, and assembles scoped context packs for runs.
The first index depends on repository size and selected sources. After that, Context Engine estimates added, modified, and deleted files and refreshes changed context instead of blindly rebuilding everything. Small refreshes are cheap; larger refreshes show AI-credit and time estimates before they run.
Enable auto refresh with a monthly AI-credit budget. MergeLoom checks vault state, detects merged changes against the indexed baseline, and refreshes stale context so new runs use recent system knowledge.
Yes, without opening write access. Approved related repositories are indexed into the same vault so Context Engine understands service, package, API, event, and dependency relationships around the target repository. Snippets from another repository still require explicit approval as run context.
Yes. Repository guidance, Markdown docs, architecture notes, context repositories, selected Confluence pages, and approved documentation sources shape runs.
Yes. Teams choose connected repositories, enable or disable Context Engine indexing per repository, add Confluence page context, and set include/exclude patterns.
Yes. The Helm chart runs Context Engine beside the self-hosted worker with a private vault volume, repository cache, worker/internal tokens, and tenant/workspace runtime scope.
Run MergeLoom on scoped work before rolling it out. You only pay when a run opens a PR/MR for review, not for seats or tickets that stop before handoff.
Cloud
Then From £4 Per PR/MR
Self Hosted
Then From £2 Per PR/MR
Paid Outcomes
No PR/MR, No Run Charge
No PR/MR, No Run Charge · No Seat Pricing · Human Review Stays In Control